Designing for resilience with cloud-native container orchestration
Written on February 18, 2026 by Jose Alejandro
In software development, shipping code is only the beginning. The greater challenge is ensuring that once software goes live, it continues to run reliably as conditions change. Modern systems are expected to scale, recover from failure, and evolve without prolonged downtime or manual intervention.
Imagine a routine deployment introduces an unexpected instability. Containers begin restarting repeatedly, and performance slowly degrades before anyone notices a problem. The team scrambles to diagnose the issue and restore service. Once stability returns, the real question becomes clear: how could the system have detected and contained the issue sooner?
Scenarios like this are exactly what container orchestration platforms are designed to address. They provide mechanisms for event driven visibility and automated health validation that allow systems to detect instability early and recover by default. For the critical government systems we support at Verdance, resilience is essential to maintaining client trust and service continuity. We have used multiple platforms such as Google Kubernetes Engine and AWS Elastic Container Service to design for reliability, but these patterns apply across platforms, independent of any specific application or implementation. At Verdance, we meet our clients where their infrastructure lives to deliver this level of reliability.
The anatomy of container orchestration
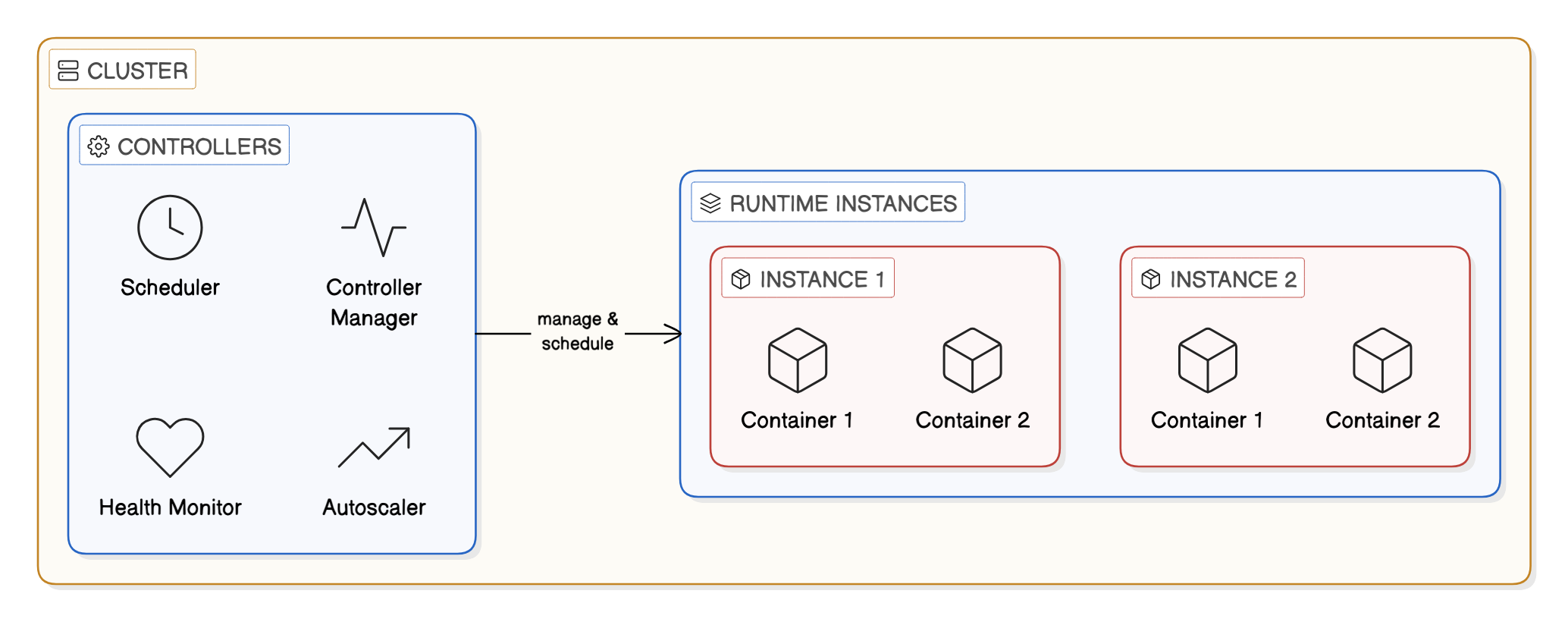
To understand how containers can help build system resilience, we can first visualize how a container orchestrator is typically organized, regardless of the specific platform. At the highest level, we have the cluster, which serves as the logical boundary for all shared compute, networking, and scheduling.
The controller (the manager)
Within the cluster, there is a management layer often called a service or deployment. These are the long-running supervisors that monitor the health of your application and ensure the desired state such as maintaining a fixed number of healthy application instances.
The execution unit (the instance)
The controller is responsible for launching individual runtime instances, often referred to as tasks or pods. These represent a single unit of work or a single instance of the application.
The container
Execution units contain one or more containers, where application code and dependencies actually run. Containers are intentionally lightweight and disposable, allowing the orchestrator to favor replacement over repair.
By choosing to make adjustments at the controller and Instance levels, we can fundamentally change how our application scales, recovers from crashes, and behaves when it encounters a problem. This approach helps our teams shift the burden of recovery from manual intervention to automated safeguards.
Techniques for deploying with confidence
We use container orchestration for more than just scheduling workloads. We design our systems to continuously monitor application health and respond to failure automatically. This approach allows us to make resilience a built-in concern rather than an afterthought.
A key idea is distinguishing between whether an application is running and whether it is ready to serve traffic. An application may need time to establish network connections, load configuration, or warm internal state before it can safely receive requests. By modeling these phases explicitly, our orchestrators can avoid routing traffic too early while still allowing the system to recover quickly from genuine failures. This separation reduces unnecessary restarts while ensuring that only stable instances handle production traffic.
To further reduce risk during deployments, many platforms provide built-in safety mechanisms that monitor rollouts as they happen. In AWS ECS (Elastic Container Service), deployment circuit breakers delegate failure detection to the service controller itself. If a new version fails to stabilize, the rollout is automatically halted before the issue propagates further. This turns deployments into monitored rehearsal, where failure is detected early and contained by default. For our client facing systems, this ability to detect and limit risk during change is essential to maintaining continuity of service.
At a finer level, container health checks allow the orchestrator to detect unresponsive or internally stuck applications for us. When a container enters an unhealthy state, it is replaced rather than repaired, often restoring service before users notice any impact. Together, these mechanisms shift the burden of recovery from manual intervention to the platform, allowing our teams to deploy more frequently with greater confidence while preserving the reliability that our clients depend on.
Event-driven monitoring and alerting
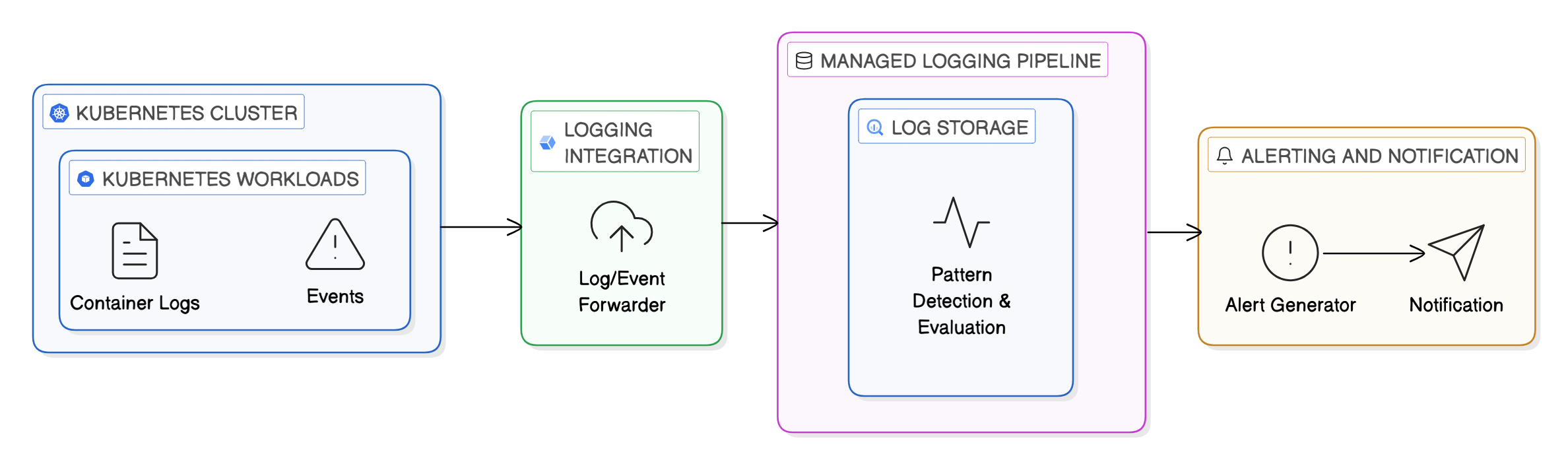
While health checks and deployment safeguards help us prevent failures from spreading, observability is what ensures failures don’t go unnoticed. In our containerized environments, many of the most critical signals are not traditional metrics but events such as unexpected container exits, tasks that fail to start, or instances that repeatedly crash and restart.
Container orchestrators emit structured lifecycle events whenever workloads change state. By treating these events as first-class signals and streaming them into a centralized logging or monitoring system, we can detect failure patterns as they emerge rather than inferring them after the fact. Repeated restarts or failed scheduling attempts, for example, often point to configuration errors, dependency issues, or resource exhaustion that warrant immediate attention.
In Kubernetes-based platforms such as GKE (Google Kubernetes Engine), these events can be captured and forwarded alongside container logs into a managed logging pipeline, where they can be correlated and evaluated in near real time. Alerts can then be generated based on patterns such as crash loops or sustained startup failures rather than isolated incidents, reducing noise while surfacing genuinely actionable conditions.
This event-driven approach shifts our monitoring from passive observation to active awareness, enabling systems to surface meaningful failures early and giving us clear signals when automated recovery is no longer sufficient. For the government agencies we partner with, this early detection of failure conditions has enabled faster responses and minimized downstream impact.
Resilience as a built-in property
Container orchestration platforms allow us to design resilience into our systems rather than reacting to failure after the fact. By combining health awareness, deployment validation, and event driven insight, we can build systems that detect instability early and respond predictably. This foundation enables our teams to innovate responsibly while maintaining consistent service delivery.
In addition, enhanced monitoring across the orchestration environment gives our government partners meaningful visibility into the health of their deployment pipelines. With clearer signals and faster detection, releases move forward with fewer surprises and less operational overhead. For the critical government systems we serve, that balance between progress and reliability is essential.
If you’re interested in helping build the future of government technology, we’d love to hear from you. Explore our open roles or reach out at hello@verdance.co.